GradMem: Learning to Write Context into Memory with Test-Time Gradient Descent
A meta-learned memory mechanism for writing context with a few test-time gradient steps.
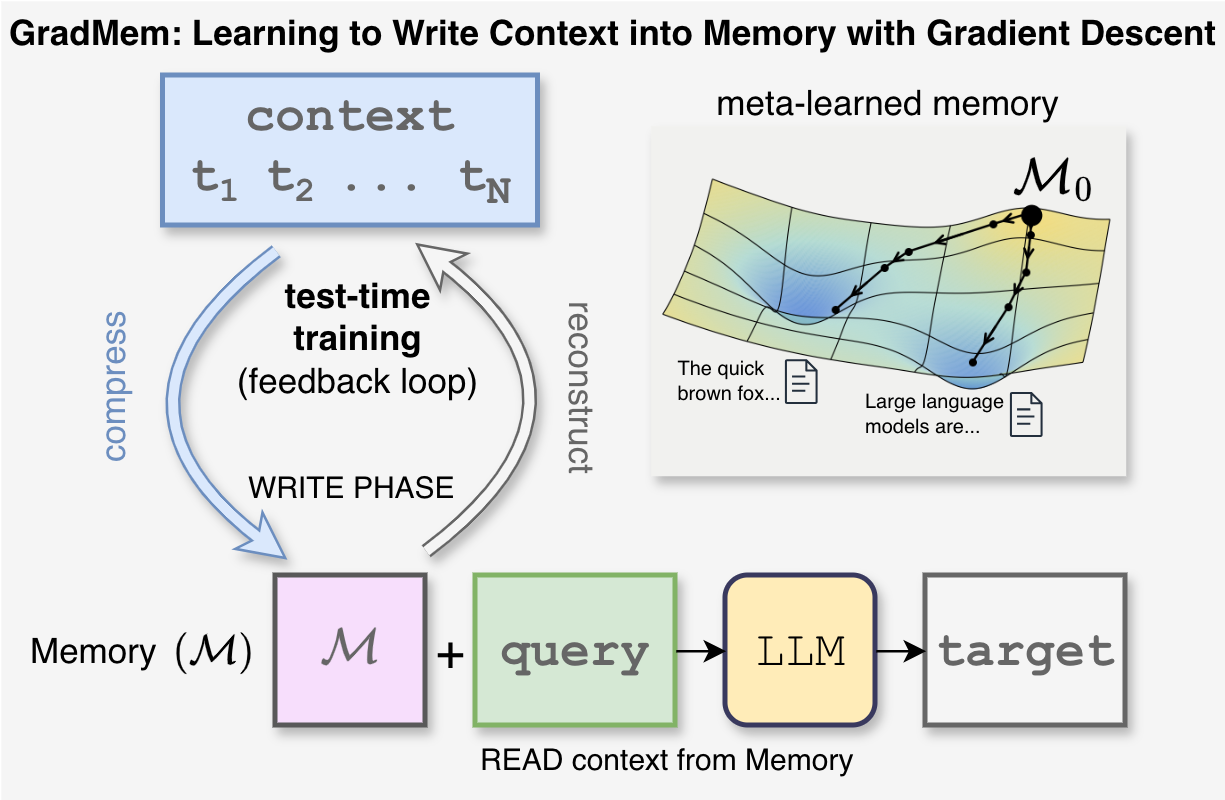
GradMem is a memory mechanism for language models that writes context into a small set of memory tokens by running a few gradient-descent steps at test time.
Instead of compressing context with a single forward pass, GradMem optimizes the memory itself with a reconstruction loss and trains the model to read from that gradient-written memory.
TL;DR
- WRITE: optimize only the memory tokens (prefix vectors) for the current context; model weights stay frozen.
- READ: remove the original context and answer from the optimized memory plus a query.
- GradMem trains the model to use gradient descent as the WRITE operation: the reconstruction loss gives direct feedback on how good the memory state is.
- Training backpropagates through the inner WRITE loop, so a few gradient steps become useful.
- More WRITE steps trade extra test-time compute for higher memory capacity.
Gradients Write More Into The Same Memory
The cleanest experiment is associative key-value retrieval. The context contains key-value pairs, the query gives a key, and the model must return the value. During READ, the original context is removed, so the answer must come from memory.
GradMem and the forward-only RMT baseline use the same base architecture (4-layer, 128-dim transformer) and the same memory size: 8 memory vectors. The main difference is the WRITE rule: RMT writes memory with forward passes, while GradMem writes memory with gradient descent.
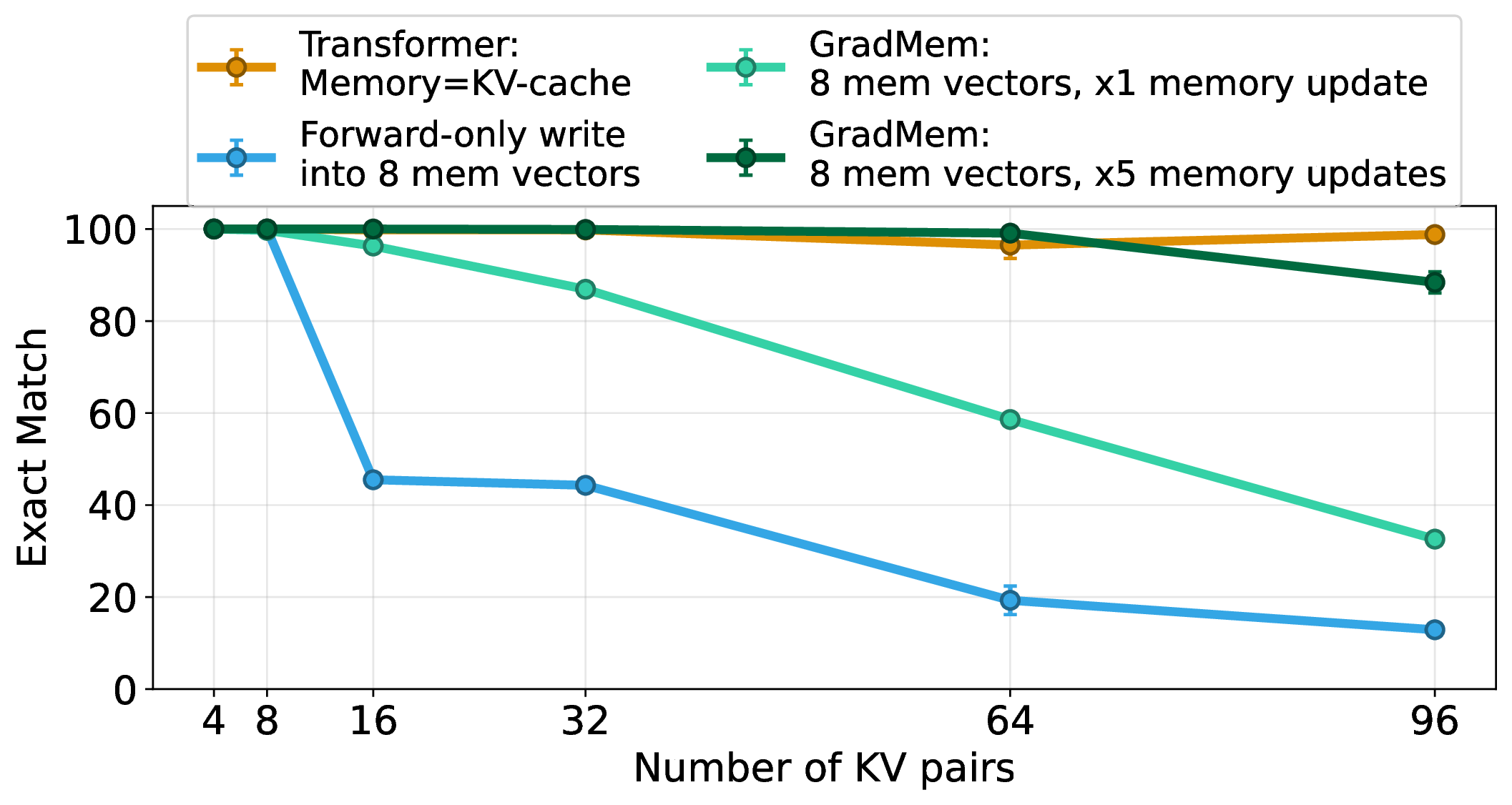
With the same 8-vector memory, GradMem retrieves 16 key-value pairs with 95% accuracy, while the forward-only write rule stores only about 8 pairs at high accuracy. This is the main result: gradient descent writes substantially more information into the same memory state.
The second result is that more WRITE steps help. With additional gradient steps, the same 8-vector memory reaches 88% retrieval accuracy at 96 key-value pairs.
So, optimization-based WRITE operation into memory gave a scalable way to spend extra test-time compute: the reconstruction loss tells the model what is still missing from memory, and each gradient step can refine the memory state.
Test-Time Scaling
The next important result is extrapolation in the number of WRITE steps. GradMem can be trained with a small number of WRITE steps, then run with more WRITE steps at inference time while keeping model parameters fixed.
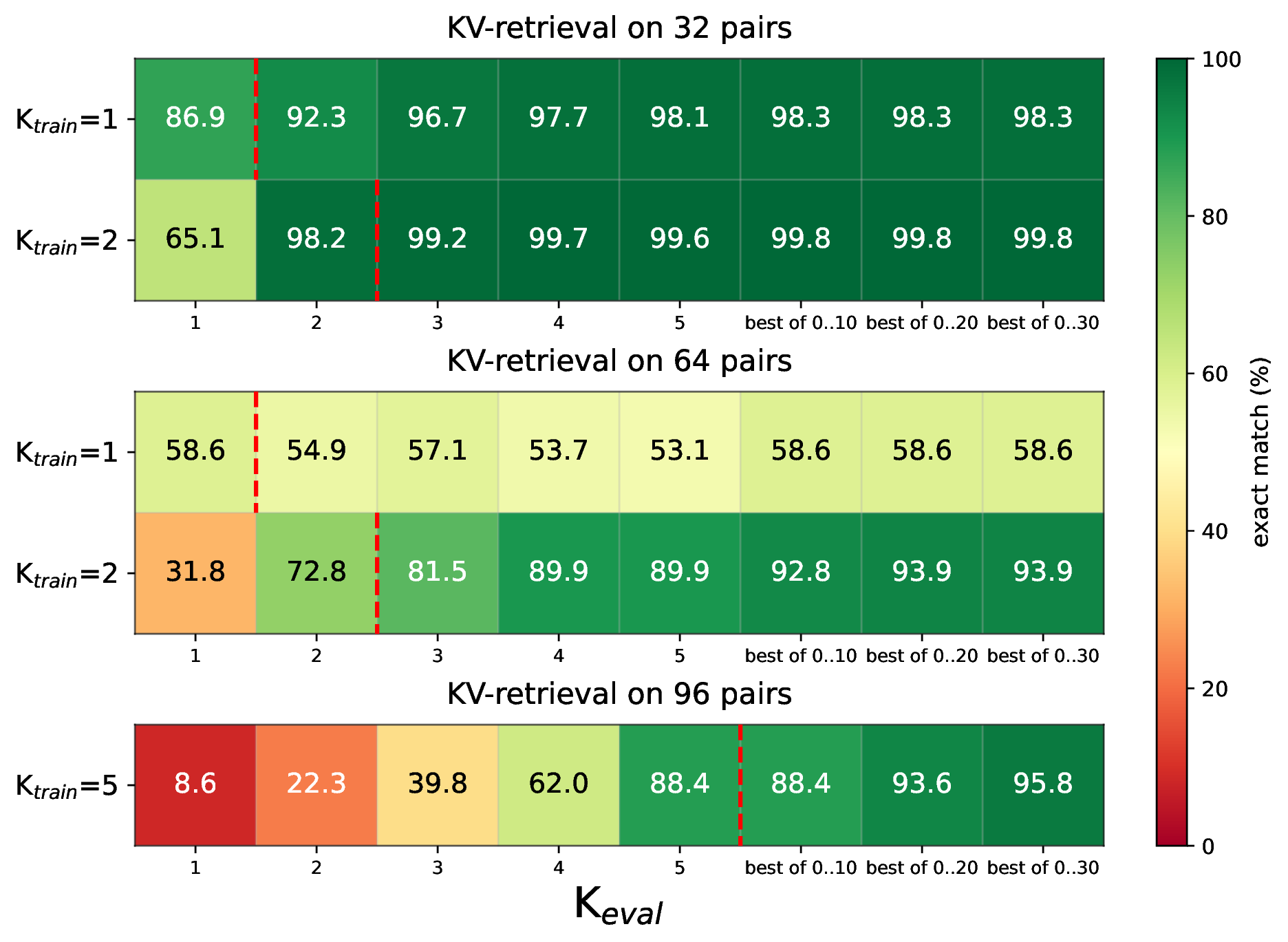
On 32 key-value pairs, a model trained with one WRITE step improves from 86.9% exact match at one evaluation step to 98.3% with more inference-time WRITE refinement. On 64 pairs, a model trained with two WRITE steps improves from 31.8% at one evaluation step to 93.9%. On 96 pairs, the same idea pushes accuracy from 8.6% at one step to 95.8%.
How GradMem Works
GradMem splits each example into a context $C$, a query $Q$, and a target $Y$. The goal is to answer from $Q$ after the original context has been removed, using only a compact memory state.
Memory is represented as $m$ prefix vectors:
\[\mathcal{M} \in \mathbb{R}^{m \times d}.\]In the WRITE phase, GradMem starts from a meta-learned initialization $\mathcal{M}_0$. Model weights stay frozen, and only the memory tokens are updated for the current context.
The WRITE objective is context reconstruction, for each token $t \in C$:
\[\mathcal{L}_{\text{write}}(\mathcal{M}; C) = -\sum_{i=1}^{N} \log f_\theta(t_i \mid [\mathcal{M}; t_{<i}]).\]Then memory is updated by gradient descent:
\[\mathcal{M}_{k+1} = \mathcal{M}_k - \alpha \nabla_{\mathcal{M}_k} \mathcal{L}_{\text{write}}(\mathcal{M}_k; C).\]After $K$ WRITE steps, the final memory is
\[\hat{\mathcal{M}} = \mathcal{M}_K.\]In the READ phase, the original context is removed. The model receives only the optimized memory and the query:
\[f_\theta(Y \mid \hat{\mathcal{M}}, Q).\]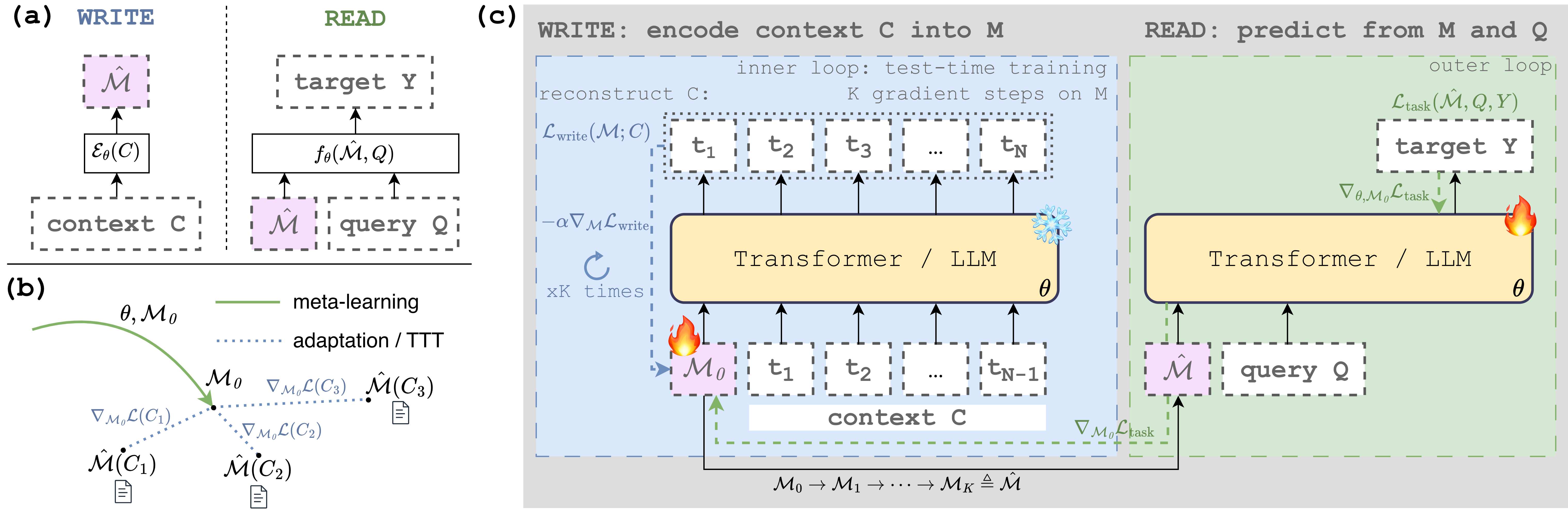
During training, we backpropagate through the WRITE updates. This trains the shared initialization $\mathcal{M}_0$ and model parameters $\theta$ so that a few gradient steps produce memory states that are useful for READ. We use the full second-order meta-gradient through the inner optimization loop.
Where GradMem Came From
GradMem grew out of a limitation that bothered me after our earlier paper, Cramming 1568 Tokens into a Single Vector and Back Again, (Kuratov et al., 2025).
In that work, we optimized input vectors with gradient descent and showed something surprising: a single vector can store a huge amount of text. For a Llama-8B model, we could cram about 1500 tokens into one optimized vector and reconstruct the text back from it.
However, these vectors were optimized for token-by-token reconstruction. The LM was not trained to treat them as drop-in context representations for downstream questions or prompts. In practice, the model could decode the original text, but it could not use the vector as a real replacement for the text it represented.
GradMem follows directly from this limitation:
If we want the model to use optimized vectors as memory, we should train it to use them. No magic should be expected.
The idea is to take the Cramming procedure and turn it into a WRITE operation. At test time, we optimize memory tokens with a reconstruction loss. During training, the model learns to READ from memory written this way.
This was the part I expected to be fragile. Meta-learning through an inner optimization loop is often tricky, and I did not initially believe the first experiments would work as well as they did. But the gradient-written memory converged much faster than my forward-only baseline, which behaved like a context encoder: read the context once, emit memory, and hope that memory is good enough.
Why Gradients Help
Forward-only encoders have no direct signal at test time that says what they failed to encode. Once the memory is emitted, the write operation is over. Gradients give feedback from an explicit loss. If the current memory does not explain some part of the context, the loss tells the write operation where memory is still missing information.
That creates a useful compute-capacity tradeoff. With a fixed memory size, we can run more WRITE steps to refine the memory. The memory initialization and model are meta-learned so a few steps are useful, and extra steps can improve capacity further.
Relation To Test-Time Training
Show discussion
GradMem is related to test-time training (TTT) because it also performs optimization at inference time. The closest starting point is Learning to (Learn at Test Time): RNNs with Expressive Hidden States (Sun et al., 2025), which updates sequence-dependent hidden state with self-supervised objectives while processing tokens.
Several recent works push this idea toward long-context modeling and memory. Titans and ATLAS learn neural memory modules that memorize at test time with update rules that resemble one optimization step (Behrouz et al., 2025; Behrouz et al., 2025). Nested Learning frames architectures as nested optimization processes (Behrouz et al., 2025). End-to-end TTT for long context and LaCT / Test-Time Training Done Right also adapt sequence-dependent state during inference (Tandon et al., 2025; Zhang et al., 2026).
GradMem belongs to this family, but uses a different interface. TTT-style methods usually maintain layer-local fast states or neural-memory modules and update them online while processing tokens or chunks. Their self-supervised losses are often local: reconstructing layer inputs, hidden activations, or other internal views.
GradMem instead performs a dedicated WRITE phase once per context. The writable state is a single input-level memory: m prefix vectors. We optimize these memory tokens directly with a model-level context-reconstruction loss, then READ from the optimized memory and query with the original context removed.
This makes the memory budget explicit and easy to reason about. More importantly, GradMem makes the number of WRITE steps an explicit test-time compute knob. Prior TTT-style memory works mostly use update rules that correspond to a single learned optimization step or online local updates. In GradMem, we can run multiple gradient steps on the same memory state, and the experiments show that these extra steps actually improve memory quality and scale capacity.
What Still Feels Open
The main engineering bottleneck is second-order training. GradMem backpropagates through the inner WRITE optimization loop, so training needs gradients through gradients. This is expensive, and it also breaks the usual fast-attention path: FlashAttention and PyTorch SDPA are designed for efficient first-order training, and do not support the double backward we need here.
We ended up implementing custom double-backward attention operations to make the experiments practical. In the paper, this roughly reduced attention backward time from about 1000 ms to 600 ms and peak GPU memory from about 60 GB to 30 GB in our setup. That made the work possible, but it also makes the next question obvious: can we keep most of the benefit while avoiding full second-order training?
I also do not think reconstruction is the final WRITE objective. It is a good starting point because it is self-supervised, task-agnostic, and simple. But the model does not necessarily need to preserve every token equally. For question answering or retrieval, a better objective might encourage memory to preserve the information that will be useful later, not just the information that is easy to reconstruct.
Another question I keep thinking about is how to scale WRITE to very long inputs. In the current setup, we compress one context into one memory state. For longer streams, we probably need something more compositional: write chunks in parallel or sequentially, merge the resulting memories, and maybe allow the same memory state to be rewritten as more context arrives. This feels important if memory is supposed to be a working state, not just a one-shot compressed representation. This also makes training harder. GradMem already backpropagates through the WRITE steps; if memory is updated across sequential chunks, training may also need to backpropagate through the chunk-to-chunk memory trajectory.
Memory also does not have to mean only input-level memory tokens. It could live in adapters, hidden states, KV-cache-like states, or some other memory state. But memory tokens have a very useful property: they are just prefix vectors, so they do not require changing transformer internals. If we move beyond memory tokens, I would want a memory form with similar simplicity: easy to attach to an existing LM and easy to optimize at test time.
Takeaway
GradMem suggests a broader direction: memory for LMs can be an optimized state, not just something produced by a single forward pass.
The current version uses memory tokens because they are simple and do not modify transformer internals. The next question is how far this idea can scale: better WRITE objectives, cheaper training, and memory forms that stay easy to attach to existing pretrained models.
Resources
- Paper: arXiv:2603.13875
- Code: github.com/yurakuratov/gradmem
- X thread: x.com/yurakuratov/status/2034989528818098615
Citation
References
- Learning to (Learn at Test Time): RNNs with Expressive Hidden StatesIn Proceedings of the 42nd International Conference on Machine Learning, 13–19 jul 2025
- Titans: Learning to Memorize at Test TimeIn Advances in Neural Information Processing Systems, 2025
- Atlas: Learning to optimally memorize the context at test timearXiv preprint arXiv:2505.23735, 2025
- Nested Learning: The Illusion of Deep Learning ArchitecturesIn Advances in Neural Information Processing Systems, 2025
- End-to-end test-time training for long contextarXiv preprint arXiv:2512.23675, 2025
- Test-Time Training Done RightIn The Fourteenth International Conference on Learning Representations, 2026