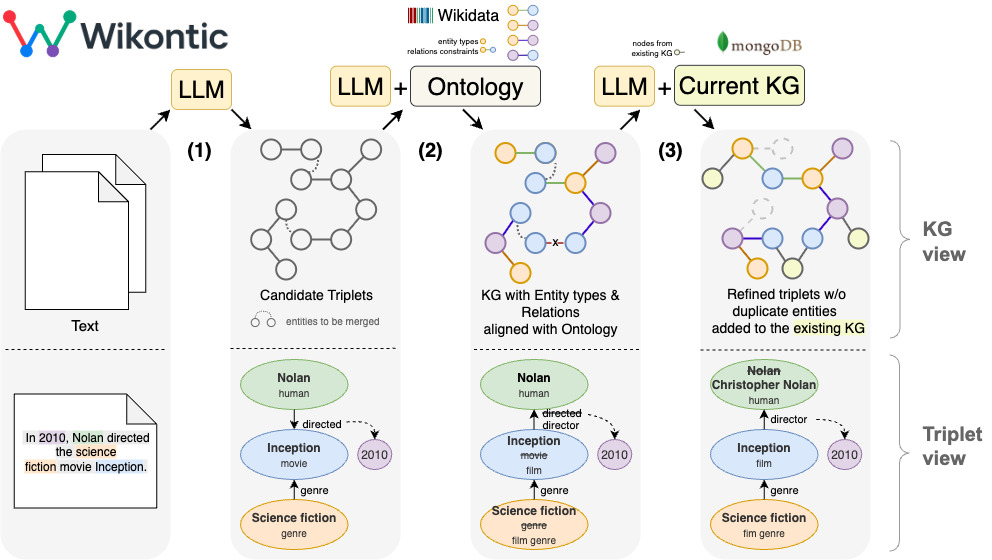
Wikontic converts unstructured text into structured knowledge graphs (Chepurova et al., 2026). It uses an ontology to control how extracted knowledge is represented: which entity types are allowed, which relations are valid, and how facts should fit together.
The pipeline extracts candidate (subject, relation, object) triplets, refines entities and relations, validates them against an Ontology (we use ontology from WikiData), and stores the resulting graph for retrieval, question answering, visualization, and any other use cases.
What It Does
Extracts candidate triplets from raw text with an LLM.
Aligns and normalizes entities and relations using constraints from Wikidata ontology.
Supports both ontology-aware and ontology-free modes, can adapt to Wikidata-like ontologies, and has LangChain integration.
Supports English and Russian languages.
Results
On MuSiQue, the correct answer entity appears in 96% of generated triplets.
In triplets-only QA (without original context), Wikontic reaches 76.0 F1 on HotpotQA and 59.8 F1 on MuSiQue.
On MINE-1, it reaches 86% information retention.
KG construction uses about 3x fewer tokens than AriGraph and under 1/20 of GraphRAG.
Wikontic For Complex QA Data Generation
Wikontic’s KGs are also useful as an intermediate representation for generating complex QA datasets and synthetic data.
Benchmarking: DRAGOn (Chernogorskii et al., 2026) builds RAG benchmarks over periodically updated corpora. Its generation pipeline extracts KGs from text and samples graph structures to create QA pairs with different complexity levels.
Training: OCC-RAG (Savkin et al., 2026) uses Wikontic KGs as one component of its synthetic data generation pipeline for multi-context, multi-hop QA. The resulting training data substantially improves compact Qwen3 models: on HotpotQA, In-Acc rises from 34.8 to 57.6 for 0.6B, and from 47.7 to 60.9 for 1.7B.
Citation
Wikontic: Constructing Wikidata-Aligned, Ontology-Aware Knowledge Graphs with Large Language Models
Alla Chepurova, Aydar Bulatov, Mikhail Burtsev, and Yuri Kuratov
In Proceedings of the 19th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers), Mar 2026
Knowledge graphs (KGs) provide structured, verifiable grounding for large language models (LLMs), but current LLM-based systems commonly use KGs as auxiliary structures for text retrieval, leaving their intrinsic quality underexplored.In this work, we propose \textitWikontic, a multi-stage pipeline that constructs KGs from open-domain texts by extracting candidate triplets with qualifiers, enforcing Wikidata-based type and relation constraints, and normalizing entities to reduce duplication.The resulting KGs are compact, ontology-consistent, and well-connected; on MuSiQue, the correct answer entity appears in 96% of generated triplets.On HotpotQA, our triplets-only setup achieves 76.0 F1, and on MuSiQue 59.8 F1, matching or surpassing several retrieval-augmented generation baselines that still require textual context. In addition, Wikontic attains state-of-the-art information-retention performance on the MINE-1 benchmark (86%), outperforming prior KG construction methods.Wikontic is also efficient at build time: KG construction uses less than 1,000 output tokens, about 3\times fewer than AriGraph and <1/20 of GraphRAG.The proposed pipeline improves the quality of the generated KG and offers a scalable solution for leveraging structured knowledge in LLMs. Wikontic is available at https://github.com/screemix/Wikontic.
@inproceedings{chepurova-etal-2026-wikontic,title={Wikontic: Constructing {W}ikidata-Aligned, Ontology-Aware Knowledge Graphs with Large Language Models},author={Chepurova, Alla and Bulatov, Aydar and Burtsev, Mikhail and Kuratov, Yuri},editor={Demberg, Vera and Inui, Kentaro and Marquez, Llu{\'i}s},booktitle={Proceedings of the 19th Conference of the {E}uropean Chapter of the {A}ssociation for {C}omputational {L}inguistics (Volume 1: Long Papers)},month=mar,year={2026},address={Rabat, Morocco},publisher={Association for Computational Linguistics},url={https://aclanthology.org/2026.eacl-long.388/},doi={10.18653/v1/2026.eacl-long.388},pages={8304--8319},isbn={979-8-89176-380-7},}
References
DRAGOn: Designing RAG On Periodically Updated Corpus
Fedor Chernogorskii, Sergei Averkiev, Liliya Kudraleeva, Zaven Martirosian, Maria Tikhonova, Valentin Malykh, and Alena Fenogenova
In Proceedings of the 19th Conference of the European Chapter of the Association for Computational Linguistics (Volume 4: Student Research Workshop), Mar 2026
@inproceedings{chernogorskii2026dragon,title={{DRAGOn}: Designing {RAG} On Periodically Updated Corpus},author={Chernogorskii, Fedor and Averkiev, Sergei and Kudraleeva, Liliya and Martirosian, Zaven and Tikhonova, Maria and Malykh, Valentin and Fenogenova, Alena},editor={Baez Santamaria, Selene and Somayajula, Sai Ashish and Yamaguchi, Atsuki},booktitle={Proceedings of the 19th Conference of the European Chapter of the Association for Computational Linguistics (Volume 4: Student Research Workshop)},month=mar,year={2026},address={Rabat, Morocco},publisher={Association for Computational Linguistics},url={https://aclanthology.org/2026.eacl-srw.48/},doi={10.18653/v1/2026.eacl-srw.48},pages={622--638},isbn={979-8-89176-383-8},}
OCC-RAG: Optimal Cognitive Core for Faithful Question Answering
Maksim Savkin, Mikhail Goncharov, Alexander Gambashidze, Alla Chepurova, Dmitrii Tarasov, Nikita Andriianov, Daria Pugacheva, Vasily Konovalov, Andrey Galichin, and Ivan Oseledets
@misc{savkin2026occrag,title={{OCC-RAG}: Optimal Cognitive Core for Faithful Question Answering},author={Savkin, Maksim and Goncharov, Mikhail and Gambashidze, Alexander and Chepurova, Alla and Tarasov, Dmitrii and Andriianov, Nikita and Pugacheva, Daria and Konovalov, Vasily and Galichin, Andrey and Oseledets, Ivan},year={2026},archiveprefix={arXiv},primaryclass={cs.CL},url={https://arxiv.org/abs/2606.00683},doi={10.48550/arXiv.2606.00683},}